Intro to Machine Learning
kaggle上的入门教程,从代码出发介绍了最基础的机器学习知识
一、模型如何工作
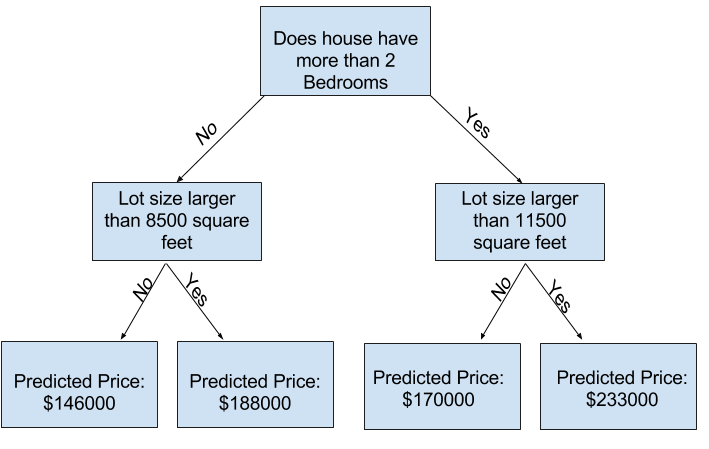
decision tree 决策树
更多的分裂来获得更多的因素,叶子部分是得到的预测结果
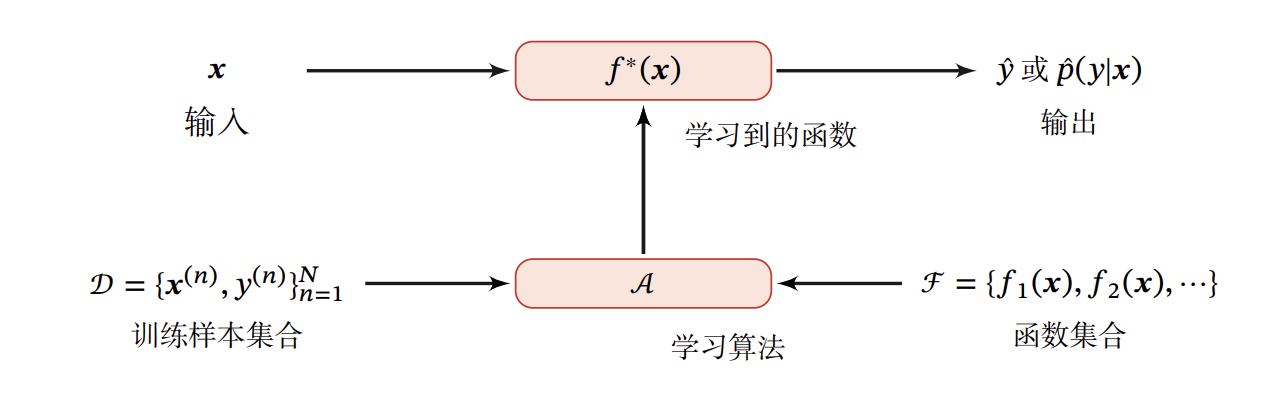
model -> train -> predict
用一张蒲公英书里的图:
二、使用Pandas库处理数据
1
2
3
4
5
6
| # 保存路径
path = '../xxx.csv'
# 在一个DataFrame(df)里读取和存储数据
df = pd.read_csv(path)
# 打印简要 DataFrame.describe()
df.describe()
|
DataFrame.describe()
1
2
3
4
5
6
7
8
9
10
11
| >>> s = pd.Series([1, 2, 3])
>>> s.describe()
count 3.0 # 非空值的数量
mean 2.0 # 平均值
std 1.0 # standard deviation 标准偏差
min 1.0 # 最小值
25% 1.5 # 第25百分位数
50% 2.0 # 第50百分位数
75% 2.5 # 第75百分位数
max 3.0 #最大值
dtype: float64 #数据类型
|
三、机器学习模型
为模型选取合适的数据(Model)
DataFrame的列:
dropna drops missing values 丢失缺失值
1
| df = df.dropna(axis=0) # na:not available
|
选择预测的目标(Prediction Target)
使用点表示法(dot notation)来选择想要预测的列,该列被称为预测目标,使用 y 来标识
1
| y = df.XXX # XXX为想要预测的列名
|
选择特征(Features)
1
| df_features = ['A', 'B', 'C'] # A、B、C是想要作为特征的列名 涉及到最优特征
|
按照惯例,使用 x 来标识
使用head()方法显示数组的头几行
建立模型
文章使用了scikit-learn来建立模型
建立和使用的步骤是:
- Define(定义): 什么类型的模型 同时也指定参数
- Fit(拟合): 从提供的数据获得模式(pattern),模型的核心
- Predict(预测): 预测值
- Evaluate(评估): 评估预测的准确率
1
2
3
4
5
6
7
| from sklearn.tree import DecisionTreeRegressor
# 定义一个模型,random_state=1保证每次运行都有相同的结果
xxx_model = DecisionTreeRegressor(random_state=1)
# Fit(拟合)模型
xxx_model.fit(x, y)
|
预测:
1
2
| print("The predictions are")
print(xxx_model.predict(x.head())) #对头几列进行预测
|
四、模型验证
衡量模型的质量,更好地迭代模型,一般通过准确性来衡量,即预测的和实际的之间的差距
首先要做的是,把模型质量总结为一种可理解的方式
有很多衡量的方法,比如:
- MAE(Mean Absolute Error)平均绝对误差
$$
\frac{1}{m} \sum_{i=1}^{m} \mid\left(y_{i}-\hat{y_{i}}\right)\mid
$$
- MSE(Mean Square Error)均方误差
$$
\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-\hat{y_{i}}\right)^{2}
$$
MAE举例:
1
2
3
4
| from sklearn.metrics import mean_absolute_error
predicted_xxx = xxx_model.predict(x) # 模型通过数据集预测
mean_absolute_error(y, predicted_xxx) # 计算mae
|
模型的实用价值体现在对新数据的预测上,所以可以在模型构建的时候取出一些数据,然后使用这些数据来测试模型对之前数据的准确性。此数据就被称为验证数据。
1
2
3
4
5
6
7
8
9
10
11
12
| from sklearn.model_selection import train_test_split
# 把数据分为训练集和验证集 random_state确保每一次
train_x, val_x, train_y, val_y = train_test_split(x, y, random_state = 0)
# 定义模型
xxx_model = DecisionTreeRegressor()
# Fit model
xxx_model.fit(train_x, train_y)
# 在验证集上计算mae
val_predictions = xxx_model.predict(val_x)
print(mean_absolute_error(val_y, val_predictions))
|
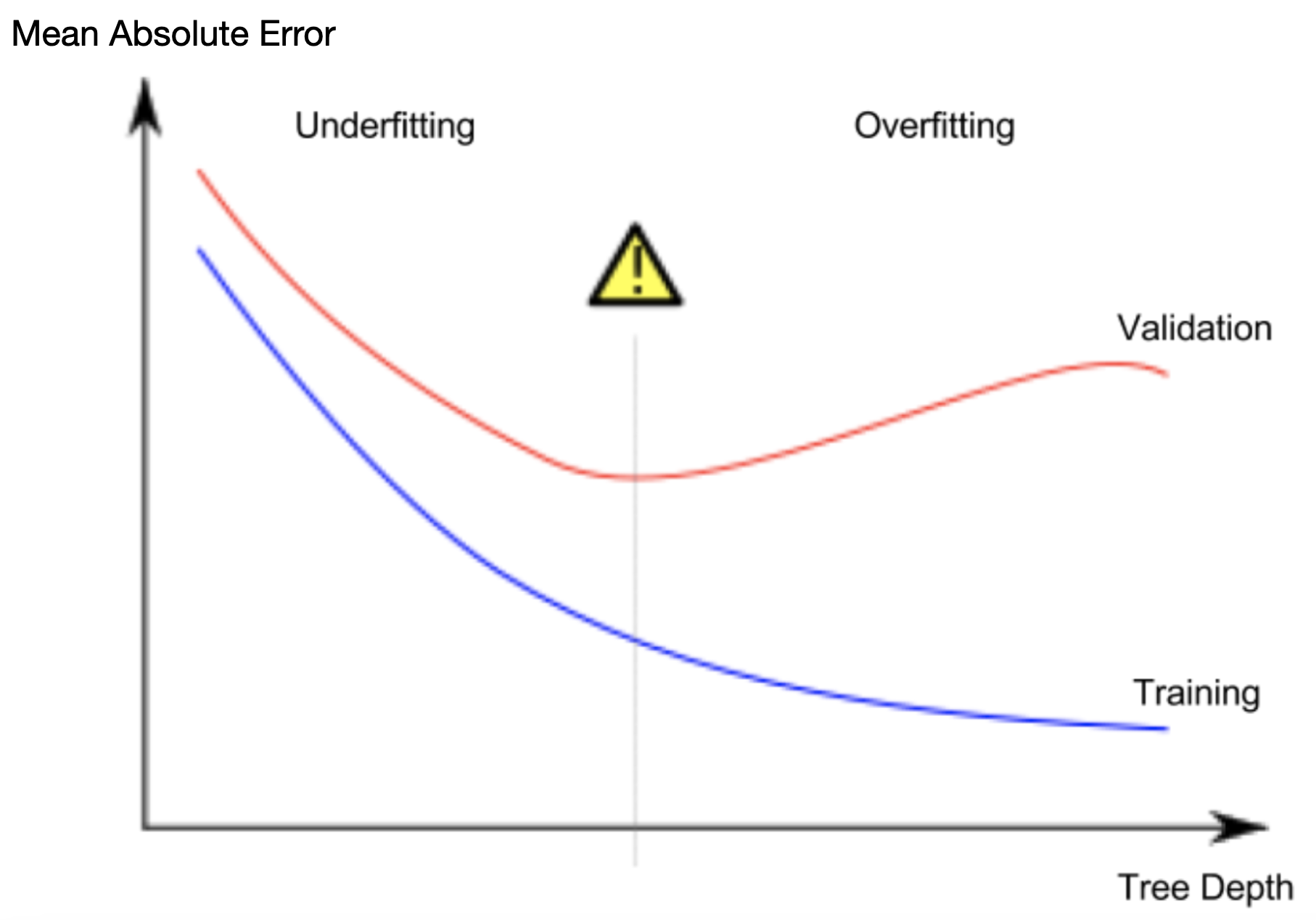
五、欠拟合和过拟合
过拟合(overfitting):即一个模型与训练数据几乎完美匹配,但在验证时在新数据时表现不佳
欠拟合(underfitting):一个模型不能捕捉到数据中重要的区别和模式,所以即使在训练数据时也表现不佳
我们要在这两个之间找到一个甜蜜点(sweet spot),方法是收集多样化的样本,简化模型,交叉检验。
六、随机森林(Random Forests)
选择性能更好的模型。如随机森林,使用许多树,通过平均每个组件树的预测值来进行预测。